
아무튼, 쓰기
100명 동시 요청 25분 → 1분, Gemini API 병목 96% 개선기 (feat. Virtual Thread의 함정) 본문
[개요]
AI 기반 퀴즈 생성 서비스에서 Google Gemini API를 활용하는 기능을 개발했습니다. 사용자가 챌린지를 생성하면, 백엔드 서버가 Gemini API를 호출하여 퀴즈를 생성하고 사용자에게 제공하는 것입니다.
문제는 Gemini API가 퀴즈를 생성하는 데 약 1분의 긴 I/O 대기 시간을 소요한다는 점이었습니다. 이로 인해 동시 사용자 요청이 몰릴 경우, 시스템 전체의 처리량이 심각하게 저하되고 사용자 대기 시간이 기하급수적으로 증가하는 병목 현상이 발생했습니다.
[요약]
- 핵심 문제: AI 모델의 응답 시간(약 1분) 동안
@Async로 할당된 플랫폼 스레드가 블로킹되어, 한정된 스레드 풀(CorePoolSize: 4)이 금방 소진되어 병목 현상. - 분석 과정: Java 21 Virtual Thread(VT) 도입을 검토했으나, Google SDK(OkHttp) 내부의
synchronized블록으로 인한 스레드 피닝(Pinning)을 식별하여 VT 도입 효과가 무력화될 것을 예측했습니다. - 최종 해결: SDK가 제공하는 논블로킹 API를 채택하여, I/O 대기 시간 동안 플랫폼 스레드를 점유하지 않도록 변경했습니다.
- 결과: 100명 동시 요청 시 최대 대기 시간을 25분에서 1분으로 96% 단축하여, I/O 대기 시간과 무관하게 안정적인 동시성을 확보했습니다.
[문제 상황 1: API의 긴 I/O 대기 시간과 동기 방식의 한계]
초기 구현은 사용자의 HTTP 요청을 받아 즉시 Gemini API를 호출하는 동기 방식이었습니다.
Gemini API는 모델 추론 특성상 응답을 받기까지 평균 1분의 시간이 소요되었습니다. 웹 애플리케이션의 일반적인 스레드(Tomcat)에서 이 요청을 직접 처리할 경우, 해당 스레드는 1분 동안 블로킹되어 다른 어떤 요청도 처리할 수 없게 되고 서비스 장애로 이어질 수 있었습니다.
[해결 방안 1: @Async를 통한 비동기 처리 및 화면 분리]
우선 사용자 요청 스레드가 1분 동안 블로킹되는 것을 막아야 했습니다.
- 화면 분리: 사용자가 퀴즈 생성을 요청하면, 서버는 즉시
202 Accepted응답을 반환하고 사용자는 퀴즈가 생성되는 동안, 다른 활동을 진행할 수 있습니다. 최대한 빨리 퀴즈를 생성하고 사용자에게 퀴즈가 생성되었다고 알림을 보냅니다. - 비동기 실행: 실제 API 호출 및 퀴즈 생성 로직은
@Async어노테이션을 통해 별도의 스레드 풀에서 비동기적으로 실행하도록 분리했습니다.
이 조치로 사용자는 즉각적인 응답을 받을 수 있게 되었고, 웹 서버 스레드가 1분 동안 대기하는 치명적인 상황은 피할 수 있었습니다.
[문제 상황 2: @Async의 한계와 플랫폼 스레드 풀 병목]
1차 해결책은 사용자의 인식 상의 대기 시간을 줄였을 뿐, 서버가 감당할 수 있는 총처리량의 문제는 해결하지 못했습니다.
저희는 비동기 스레드 풀의 최대 크기를 corePoolSize: 4로 설정해서 동시에 4개의 퀴즈만 생성할 수 있었습니다.
부하 테스트를 통해 100명의 사용자가 동시에 퀴즈 생성을 요청하는 시나리오를 시뮬레이션했습니다.


- 1 API 호출 = 1분
- 동시 처리 가능 개수 = 4개 (스레드 풀 크기)
- 서버의 시간당 처리량 = 4 요청 / 1분
100명의 요청을 처리하기 위한 총 시간은 (100 / 4) * 1분 = 25분이었습니다.
즉, 100번째 사용자는 퀴즈가 생성되기 시작하기까지 24분을 기다려야 하며, 퀴즈를 받기까지 최대 25분의 대기 시간이 발생합니다.
문제의 본질은 @Async가 I/O 대기를 해결해주지 않는다는 점입니다. 단지 블로킹이 발생하는 위치를 웹 스레드에서 비동기 스레드로 옮겼을 뿐, 비싼 플랫폼 스레드가 1분 동안 아무 일도 하지 않고 I/O를 기다리는 자원 낭비는 동일했습니다.
[해결 방안 2: I/O 병목 근본적 해결을 위한 탐색]
문제는 I/O 대기 시 스레드 점유였습니다. 이 문제를 해결하기 위해 Java 21에서 도입된 가상 스레드(Virtual Threads)를 최우선으로 검토했습니다.
(1차 검토) Java 21 가상 스레드(Virtual Threads) 도입
가상 스레드는 I/O 대기 시(예: API 호출) 플랫폼 스레드에서 분리(unmount)되어 플랫폼 스레드를 반납합니다. 100만 개의 가상 스레드가 동시에 I/O 대기 상태여도, 실제 플랫폼 스레드는 소수만으로 감당 가능합니다.
하지만, 자바 21의 가상스레드는 함정이 있습니다.
가상 스레드는 코드 블록이 synchronized 키워드로 감싸져 있거나 native 메서드를 호출할 때 플랫폼 스레드에서 분리되지 못하고 고정(Pinning)됩니다.
Google Gemini SDK의 내부 구현을 분석한 결과, SDK가 의존하는 OkHttp 라이브러리 내부 여러 곳에 synchronized 블록이 존재하는 것을 확인했습니다. (깃허브 이슈를 뒤져봤는데, OKHttp도 pinning 병목을 없애기 위해서 대대적인 리팩토링 작업을 하려다 24부터 Synchronized pinning 문제가 해결되어서 리팩토링을 하지 않았다고 합니다.)
이는 만약 synchronized 블록 내부에서 I/O 대기가 발생할 경우, 가상 스레드가 플랫폼 스레드에 고정되어 1분 동안 스레드를 반납하지 못함을 의미합니다. 결과적으로 가상 스레드를 도입하더라도 플랫폼 스레드 풀(기본 ForkJoinPool)이 1분 동안 블로킹되어, 동일한 병목 현상이 발생할 것이라 판단했습니다.
synchronized로 인한 피닝 문제는 Java 24에서 해결되었으나, 현재(Java 21)로서는 한계였습니다.
(2차 검토) 기술적 Trade-off 분석
SDK + 가상 스레드의 한계에서 다음과 같은 대안들을 검토했습니다.
[대안 1 - 채택x] 가상 스레드 + REST API 직접 호출
Google SDK를 포기하고, WebClient를 사용해 Gemini REST API를 직접 호출합니다.가상 스레드의 이점을 100% 활용할 수 있지만, API 명세 변경, 직렬화/역직렬화, 오류 처리를 모두 직접 구현하고 관리해야 합니다. SDK가 제공하는 편의성을 모두 포기해야 했습니다.
[대안 2 - 채택x] Java 25 마이그레이션
피닝 문제가 해결된 Java 25로 마이그레이션 합니다. SDK를 유지하면서 가상스레드의 이점을 사용할 수 있지만, 안정적인 마이그레이션을 위해서는 의존성 체크, 카나리 배포 등 비용이 높습니다.
[대안 3 - 채택o] SDK의 논블로킹(비동기) API 사용
SDK 문서를 재검토하여, I/O 대기 시 스레드를 점유하지 않는 비동기(Non-Blocking) 호출 방식이 있는지 확인했습니다. 다행히 Google SDK는 generateContent()(동기) 외에 generateContentAsync()(비동기) 메서드를 제공하고 있었습니다.
[최종 해결] 논블로킹(비동기) SDK 호출
최종적으로 @Async + generateContentAsync() 조합을 선택했습니다.
generateContentAsync() 메서드는 호출 즉시 ListenableFuture 객체를 반환하며, 실제 I/O 작업은 SDK 내부의 I/O 스레드 풀(OkHttp의 Dispatcher)에서 수행됩니다.
@Async 스레드 풀(MaxPoolSize: 4)은 1분간의 I/O 대기를 수행하는 것이 아니라, 100ms 미만의 작업 등록하고 즉시, 또 다른 요청의 AI 요청을 보냅니다.
[결과 / 성능 테스트]
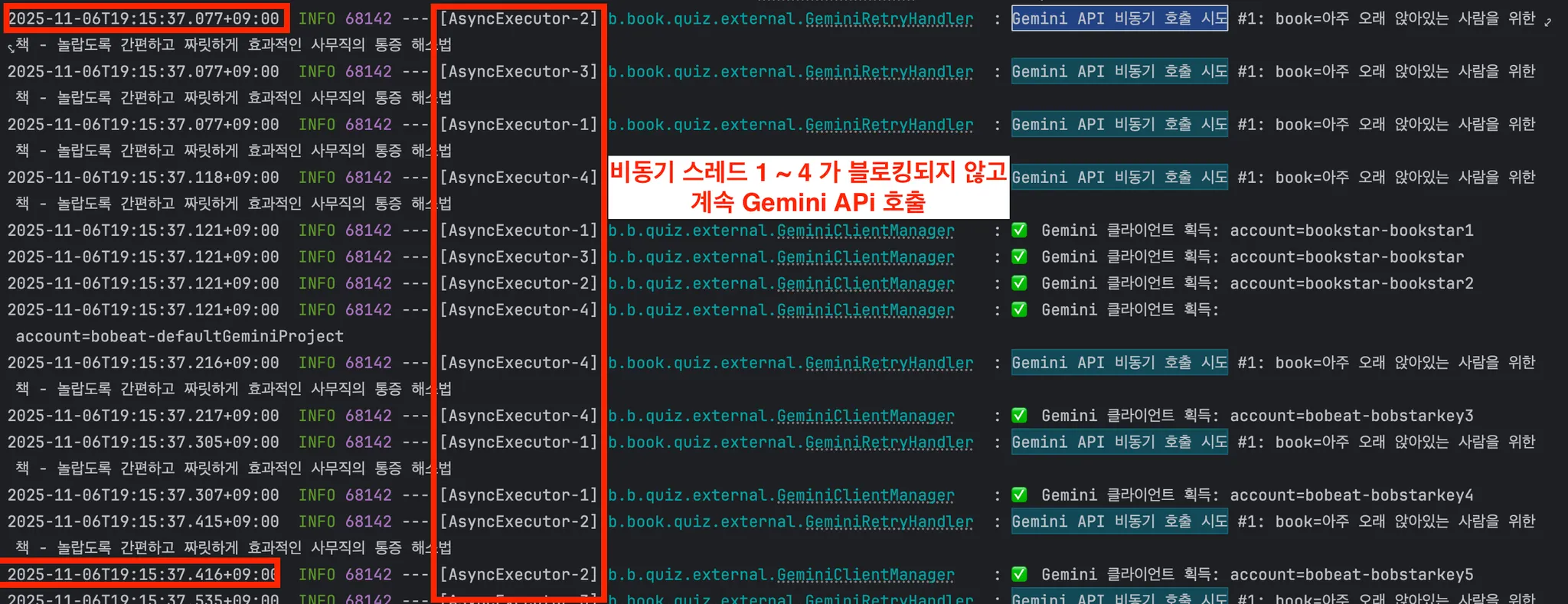
동일하게 100명 동시 요청 부하 테스트를 진행했습니다.
- [Before] Blocking SDK: 100번째 사용자는 약 25분 후에 퀴즈를 받았습니다.
- [After] Non-Blocking SDK: 100번째 사용자도 약 1분 후에 퀴즈를 받기 시작했습니다.
결과적으로 100명 동시 요청 시 최대 대기 시간을 25분에서 1분으로 96% 단축했습니다. 스레드 풀 크기와 관계없이 I/O 병목이 해소되었으며, 동시 요청도 안정적으로 처리할 수 있는 확장성을 확보했습니다.
I/O병목에는 가상 스레드가 정답...이지만, 만능은 아니다.
가상 스레드는 I/O 바운드 작업의 성능을 올려줄 좋은 기술임은 분명합니다. 하지만 가상스레드를 분석하지 않고 맹목적으로 도입했다면, synchronized로 인한 피닝(Pinning) 함정에 빠져 아무런 성능 향상을 얻지 못한 채 복잡성만 증가시켰을 것입니다. 새로운 기술을 도입할 때는 반드시 내부 구현과 한계점을 명확히 분석해야 함을 다시 한 번 느꼈습니다.
'스프링' 카테고리의 다른 글
| 왜 내 readOnly는 슬레이브로 가지 않는가? (0) | 2025.11.12 |
|---|---|
| [디프만, 밥토리] Hibernate 벡터, "묻고 double[]로 가!" 가 아니라.. float[]로 가! (0) | 2025.11.07 |
| @Transactional에서 try-catch를 썼는데 500 에러? (0) | 2025.11.06 |
| Spring 이벤트, 혹시 이렇게 쓰고 계신가요? (Fat Event 피하기) (0) | 2025.10.23 |
| (오픈소스 기여까지)Spring JDBC 배치 처리 최적화: 27초에서 1초로 (1) | 2025.10.09 |



