HashMap은 Key와 Value가 짝 지어진 자료구조입니다.
HashMap 동작원리
- HashMap은 key의 HashCode을 이용해서 시간복잡도 O(1)으로 value를 찾아낸다.
- HashCode를 인덱스로 삼는 배열 자료구조이다.
- 실제 계산은 HashCod % size 이다.
- 나머지 연산을 하는 이유는 배열의 인덱스 중 하나로 매핑시키기 위함이다.
- 특정 값에 대한 해시값 만약 3288449라는 값을 배열의 인덱스로 사용한다면 최소 3288449 크기의 배열을 생성해야한다. 메모리를 많이 차지할것이다. 때문에 이 값을 배열의 Size로 나눈 나머지를 구하고 이를 Index로 사용하는 것이다. 만약 HashMap 내부 배열 Size가 10이라면 3288449 % 10 = 9. 즉 9라는 인덱스를 갖게 된다.

여기서 눈치가 빠르신 분들은 의아함을 느꼈을 수도 있습니다.
Hash값은 고유하지 않은데 다른 데이터끼리 Hash값이 같으면 어떡하지? 라는 의아함이요
위 의문점을 직관적으로 이해시키켜 드리기 위해 예시를 가져왔습니다.
public class Main {
public static void main(String[] args) {
String str1 = "hello";
String str2 = "world";
int num1 = 42;
int num2 = 27;
// Hash codes for strings
int strHash1 = str1.hashCode();
int strHash2 = str2.hashCode();
// Hash codes for integers
int intHash1 = Integer.hashCode(num1);
int intHash2 = Integer.hashCode(num2);
System.out.println("Hash code for \"" + str1 + "\": " + strHash1);
System.out.println("Hash code for \"" + str2 + "\": " + strHash2);
System.out.println("Hash code for " + num1 + ": " + intHash1);
System.out.println("Hash code for " + num2 + ": " + intHash2);
// Example of a hash collision
String str3 = "Aa";
String str4 = "BB";
System.out.println("Hash code for \"" + str3 + "\": " + str3.hashCode());
System.out.println("Hash code for \"" + str4 + "\": " + str4.hashCode());
}
}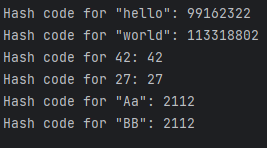
보시는 바와 같이 "Aa", "BB"의 해시코드 값이 같습니다. 이런 상황을 해쉬충돌이라 부릅니다
JAVA 해쉬충돌 해결법
- 자바는 해쉬충돌을 Seperate Chaining으로 해결합니다.
- Separate Chaining
- D와 C와 B의 해쉬값이 같으면 연결리스트로 1이라는 인덱스에 배열로 구성합니다.
- 해쉬 값이 겹치지 않는다면 조회 할 때 시간 복잡도는 O(1)이지만 겹친다면, 해쉬값으로 인덱스를 찾은 후 연결리스트를 타서 key값으로 해당 요소를 찾습니다. 때문에 최악의 경우는 O(n)이 될 수 있습니다. 여기서 최악의 경우는 1이라는 인덱스의 A,B,C,D가 모조리 있는 경우입니다.
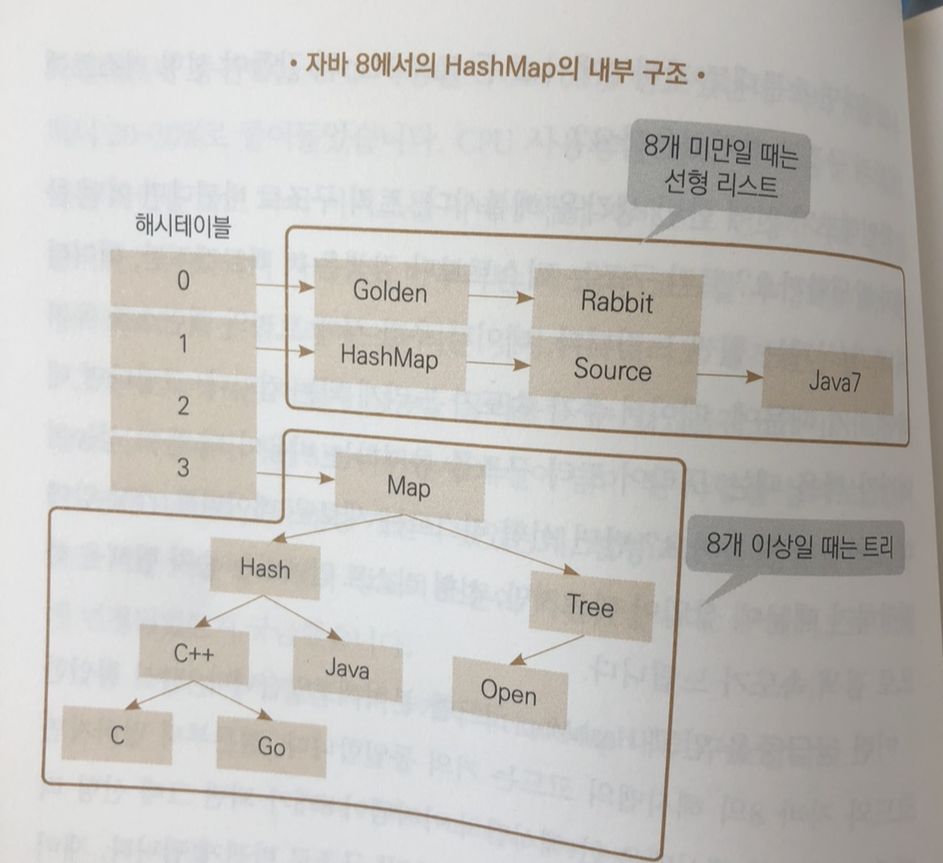
- 이 문제를 해결하기 위해 HashMap은 해쉬 충돌이 적은 해쉬함수활용, 보조 해쉬함수 사용, 해쉬 버켓 확장 재할당, chain을 tree(레드 블랙 트리)로 바꾸는 등의 여러 방식을 활용하고 있다.

레드 블랙 트리 활용방식
리사이징
배열의 사이즈는 초기화 시 정해진다. 기본 생성자를 통해 HashMap을 생성한 후 put 메서드를 실행하면 기본사이즈인 16 사이즈의 Node 배열이 생성되고 리사이징 임계 값으로 12(0.75*16)가 결정된다. 여기서 리사이징 임계값이란 배열을 리사이징하는 기준값을 뜻하며 현재 배열길이의 두 배로 리사이징한다. 12개를 초과할 경우 배열을 16의 2배인 32 사이즈로 리사이징 하는것이다.
재배치
리사이징을 할 경우 두 배 사이즈로 배열을 재생성하고 데이터를 이관시킨다고 했다. 이는 기존에 저장되어 있던 Node들의 Index가 재배치되어야 함을 의미한다. Index를 구하는 공식은 hashCode % Size 이므로 Size가 바뀐다면 Index도 바뀌어야하기 때문이다. 예를들어 사이즈가 10 일때 해시값 5755151를 통해 구한 Index는 1이지만, 사이즈가 20일 경우 Index는 11이 된다.
'CS > 자료구조' 카테고리의 다른 글
| Bitset 자료구조란 (0) | 2025.04.04 |
|---|---|
| LiskedList vs ArrayDeque vs 배열 (0) | 2024.08.01 |
| Iterator에 대하여 (0) | 2024.04.16 |
| Set에 대하여 (0) | 2024.04.16 |
| List <-> 배열 변환하는 법 (1) | 2024.03.29 |



